Está claro que uno de los productos/servicios de moda que se está poniendo en las grandes corporaciones es Kubernetes. Motivos casi todos los sabemos sin mirar ningún sitio de internet: ahorro de costes, escalabilidad y mejora en los despliegues. En este artículo nos vamos a centrar en que debes de conocer de Kubernetes o k8s en adelante, para que puedas sacar partido a AKS y no mueras en el intento.
K8s tiene una curva de aprendizaje un tanto elevada, más que nada por el desconocimiento de algunos conceptos, o incluso es posible que estos conceptos no lo entiendas hasta que realmente no tiene tu aplicación en producción o es posible incluso que las suposiciones iniciales de las que se partía no eran correctas y tengas que volver a recrearlo (no te preocupes, entra dentro del aprendizaje).
Para empezar con el desarrollo debemos tener claro cuáles son los conceptos básicos que tiene un clúster. Los más nombrados, de menos a mayor agrupación son:
-
Pod => Mínima unidad funcional, encapsula el contenedor o contenedores que se van a ejecutar.
-
Replica Set => Define con campos, incluyendo un selector que especifica cómo identificar los pods que pueden adquirir, un número de replicas que indica cuantos pods debe mantener, y una plantilla de pod que especifica los datos de los nuevos pods que debe crear para cumplir el criterio del número de réplicas.
-
Deployment => Declaración de cómo se comportan y que elementos tienen asignado los pods/ replica set en el clúster.
-
Node => Una máquina en algún lugar con una CPU y memoria asignada.
-
Node Pool (grupo de nodos) => Es una agrupación de Nodos de la misma característica.
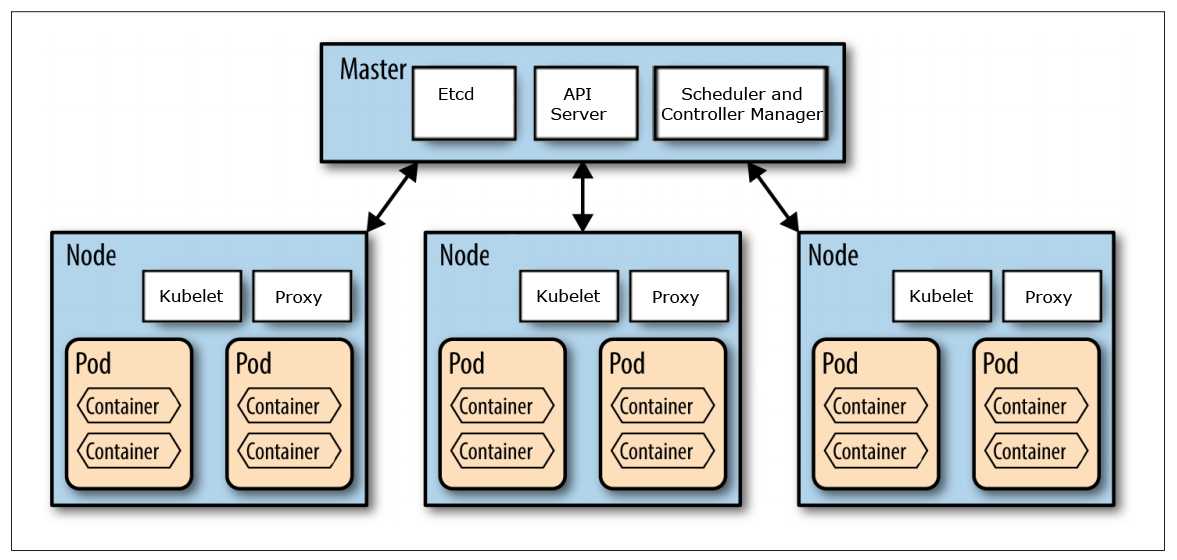
Creando Nodos y Grupos de Nodos
Una vez tenemos claro los conceptos básicos, vamos a empezar con que es lo primero que tenemos que indicar en el momento que vamos a crear nuestro AKS. Lo primero que tenemos que decidir es cuantos Node Pool queremos crear y el tamaño de la maquinas que formarán esos nodos.
¿Qué cosas debemos de saber primero? Lo primero de todo es que tengamos el concepto de esta agrupación y que consecuencias tienen. Como buena práctica mínimo, independiente del entorno, siempre creo dos grupos de nodo. El primero se llama nodo del sistema y en contendrá todo lo necesario para que nuestro sistema funcione, como por ejemplo la telemetría, alertas, seguridad, servidores, secretos como puedan ser prometheus, open telemetry, nginx, cert manager, linkerd además de todo lo que trae por defecto cuando creas el clúster. Luego ya el segundo sería el nodo que contenga nuestro desarrollo.
¿Tienen que ser dos node pool? No, mínimo son dos lo que recomiendo. Luego ya las agrupaciones que se tengan entre ellos ya dependen de las necesidades y de cómo quieras organizar el clúster. Por ejemplo, imagina que quieres hacer dos separaciones en tu aplicación. Por un lado, quieres tener la parte frontal y que expongas al exterior y luego por otro los procesos de backend ponerlos en otro grupo de nodos. Esa separación ya es más dependiendo de cada caso, pero se debe tener en cuenta que si hacemos más la separación se crearán más nodos y eso implicará que el costo de nuestro k8s será mayor. También luego dependiendo de nuestras necesidades se pueden crear más nodos e ir moviendo pods de un nodo a otro no es una tarea muy difícil, así que si dudas de cuantos creas, como consejo se conservador al inicio y conforme veas que se comporta tu aplicación y como va escalando, des escalando y que procesos son los que más recursos necesitan ya posteriormente vas creando estas nuevas agrupaciones.
¿Esto es lo único que debemos de saber los node pool? Obviamente la respuesta es no. El tamaño que tiene cada nodo es bastante importante porque en base a las características que le indiquemos a la máquina tendrá cabida un mayor número de pods. Al final el escalado de un clúster depende del número de nodos que tengas (que no pods, puedes escalar a nivel de pods, pero eso no implica que los nodos estén escalando). Es importante tenerlo claro porque solo pagamos por los nodos que estamos consumiendo.
Si ponemos una maquina muy grande implicará que tiene un número muy grande de pods, para la elección de este tipo de maquina debemos tener claro que tenemos muchos que tengan muchos recursos asignados, de tal forma que cuando escale este nodo cumpla con bastante de su capacidad, porque si no es posible que escalemos y durante el tiempo que se está creando el nodo no estemos sacando el máximo a ese nodo. Si por el contrario ponemos una maquina más pequeña, esto implicará que igual cuando tengamos una carga de trabajo elevada es posible que escalemos con varios nodos, pero estos nodos están más completos. En este punto también depende de cómo te llegue la carga de trabajo, imagina que llega Black Friday pues igual ya prefieres estar con esa capacidad, y por eso mejor una maquina grande o por el contrario si es algo más como un videojuego donde el número de usuarios por regla general suele ser de forma progresiva a lo largo del día y tu sistema se puede ir adaptando de una forma gradual.
Ahora bien, estamos indicando que depende de los recursos que tengan nuestros pods, pero si estamos creando ahora el desarrollo no sabemos que recursos vamos a asignar. La primera elección de estos recursos siempre es algo estimada/orientativa, posteriormente es conveniente hacer unos tests de carga para saber cómo se comporta nuestro clúster con el desarrollo realizado. Esta primera asignación, aunque no acertemos se puede modificar una vez sepamos cual es el comportamiento real de producción, eso sí, el único inconveniente es que habrá que recrear el grupo de nodos donde están esos desarrollos. Si el clúster esta bien montado esto no debe de implicar ninguna parada del servicio.
Resources o que tamaño debe tener cada POD
Hasta este momento hemos visto como la estructura de más alto nivel en k8s, pero al final lo que ocupa el espacio de estos nodos son los pods que corren dentro de ellos. La pregunta que muchos desarrolladores se hacen es: ¿cuántos pods me pueden caber dentro de un nodo? Es obvio que lo primero que contestaremos depende del tamaño del nodo, pero hilemos un poco más la pregunta. ¿En dos nodos que tienen el mismo tamaño caben el mismo número de pods? Obviamente la respuesta es depende y aquí si que entra depende de los resources que tiene asignado cada pods. Pero ¿que son los resources? Podemos decir que son los recursos que tiene asignado cada pod en el clúster. Estos recursos son memoria y cpu. La memoria se mide en bytes y la cpu cada unidad de cpu que se asigna corresponde con 1 vcpu/core. Dependiendo de la asignación que hagas y del tamaño de tu maquina cabrán mas o menos pods en tu clúster.
La asignación de estos resources, aunque no es obligatoria, si es recomendada que lo hagamos. Si tu no estableces un tamaño mínimo de memoria y cpu entre tus pods eso implicará a no llevar un control de lo que se esta ejecutando en tu clúster y si la memoria o cpu empieza a escasear, el comportamiento más lógico que tiene tu clúster es matar pods que tengan el máximo de memoria o cpu y entonces no controlas tu la importancia de tu aplicación.
También es importante esta asignación, porque cuando haces un deployment en Kubernetes y le asignas un resource de x Memoria y x CPU, Kubernetes no lo despliega si no tiene esos recursos disponibles. En el caso de que le permitamos que cree más nodos de forma dinámica, aprovisionará un nuevo nodo y posteriormente terminará de ejecutar el deployment. Junto con los resources también tiene los limits, los limites es el valor como máximo que le permites que llegue la CPU y la memoria antes de reiniciar el pod y devolverle a su tamaño original. La diferencia de los limites hasta los resources no es un espacio que k8s te garantice que sea tuyo, si el clúster tiene esos recursos disponibles te los asignará, pero nunca creará un nuevo nodo por esto acción. Si hiciéramos la comparativa/diferencia con un despliegue en un servidor Windows con un IIS tradicional, seria tu en el IIS instalas todo lo que necesitas, pero el reparto de los recursos entra las aplicaciones lo hace Windows según su criterio y no según las necesidades que tiene tu desarrollo. Esto es una gran ventaja de Kubernetes respecto al alojamiento tradicional.
Ahora bien, cual es el problema que nos podemos encontrar con esta asignación. El sobre asignar recursos que luego realmente no estén utilizando tu aplicación. Pongamos un ejemplo, implementamos una API y esperamos consumir unos resources de CPU de 0.2 vcores y cuando estas observando la gráfica la media que tiene a lo largo de un día es de 0.05. Este implica que por cada pod de este tipo estamos desaprovechando este espacio. Muchos de vosotros diréis, y con razón, pero que ocurre si viene una carga de trabajo bastante elevada, como puedo soportarla si he ajustado estos límites a lo justo. La cuestión no es ajustar al limite que en cuanto tengamos una carga de trabajo elevada nuestro desarrollo se queda colgado, sino tener un buen plan de escalado y tener claro cual es el valor promedio y el margen que puedo permitir. Es decir, imaginaros el ejemplo anterior, mi consumo es 0.05 vcores de media, pero en el momento que tengo una carga de trabajo elevada estos se ponen en 0.1 vcores. ¿Qué soluciones podremos optar? Poner un 0.08 vcores de resource y tener una política de escalado de cuando el porcentaje de CPU este aun 75% de lo que se ha reservado escale. De esta forma en el momento que mi pod exceda su media normal creo un pod nuevo para poder hacer frente a esta carga. Otro escenario, que también nos podríamos plantear es jugar con los límites, sabemos que el máximo de consumos de vcores es 0.1 pues permitimos que llegue a este valor antes de matar el pod. Ahora bien, que ocurre si ese día tenemos una carga superior y no hemos indicado que escale, pues que nuestro sistema se caerá. Siempre es importante tener en cuenta cuanto permitimos crecer a nuestro sistema. Un sistema que aprovecha bien sus cargas de trabajo es aquel que en momentos del día vemos que su número de nodos que tiene aumenta, pero cuando pasa esta carga de trabajo disminuimos el número de nodos.
¿Porque es importante tener ajustado en un tamaño correspondiente cada pod? Porque este tamaño que tenemos lo que nos indica es la capacidad que tenemos disponibles en nuestro clúster, si tenemos un clúster generalmente con prácticamente todos los resources reservados, pero no utilizados, en el momento de escalar siempre creará un clúster, aunque no se este utilizando todo el potencial de este. Es muy frustrante ver que tu sistema no se comporte realmente como quieres o como debería comportarse debido a un mal ajuste de estos valores.
Otros aspectos para tener en cuenta: la topología de los pods
En este articulo nos estamos centrados en los primeros elementos con los que nos topamos cuando empezamos a trabajar con Kubernetes, pero no son los únicos. En todo desarrollo que ponemos en producción debemos tener en cuenta aspectos relativos a la alta disponibilidad del clúster. Hemos indicado que tenemos grupos de nodos, nodos y pods, pero en ningún momento hemos indicado como queremos que se distribuyan estos pods en los nodos. Pues bien, la topología de donde queremos que se posicionen nuestros pods es algo esencial para ello.
Pongamos el caso que tenemos un servidor web que indicamos que queremos un mínimo de 10 nodos y que escale hasta un máximo de 20 nodos. Tenemos 2 Pools de Nodos, y estos además tienen 3 nodos cada uno. Imaginar que no indicamos ningún valor ni ninguna configuración y tenemos la "fortuna" que todos nuestros pods se provisionan en un único nodo, todo sabemos lo que pasará si este nodo tiene algún percance, ¿no?
Para ello en el deployment hay una propiedad que se llama topologySpreadConstraint en la que podemos configurar como queremos que se comporte los pods. Esta topología puede variar depende de cada aplicación, lo que quiere indicar es la relación de cada pod que se va a crear con los otros pods que están en el cluster. Los campos que podemos configurar son los siguientes:
-
maxShkew => describe el grado en que los pods pueden estar desigualmente distribuidos.
-
minDomains=> indica un número de dominios elegibles. No es un obligatorio.
-
topologyKey=> Es la Key de las etiquetas de los nodos. Se considera que los nodos que tienen una etiqueta con esta clave y valores idénticos están en la misma topología.
-
whenUnsatiftiable => Indica como tratar un pod si no satisface la restricción de distribución. Puede tener dos valores:
-
DotNotSchedule (por defecto) indica al planificador que no lo programe.
-
SheculeAnyway indica al planificador que lo programe, pero dando prioridad a los nodos que minimicen la desviación.
-
-
labelSelector => Se utiliza para encontrar con los pods coincidentes.
-
matchLabelKeys => Es la lista de label keys que se utilizarán para seleccionar los pods sobres los que se aplicará esta topología
-
nodeAffinityPolicy => Indica como trataremos al pod cuando se calcule la dispersión de la topología del pod. Se pueden incluir todos los pods que incluyan con el NodeSelector o NodeAffinity o se pueden ignorar este valor y que se tenga en cuenta todos los pods.
-
NodeTaintsPolicy => Indica como queremos tratar lo nodo tains para el cálculo de la topología de los pods.
Esta topología es algo muy importante como hemos comentado para tener en cuenta a la hora de buscar la alta disponibilidad de nuestro clúster, pero también tiene unos inconvenientes. Una mala configuración puede hacer que un nodo no desescala y que estemos consumiendo unos recursos que no se estén aprovechando. Imaginar que configuramos que queremos tener un pod en cada nodo de los que tenemos y que el número de pods mínimos que tenemos en ese nodo es 1. Que ocurre si escala y se crea un nuevo nodo y aprovisiona el pod. Que por la propia política de la topología del clúster no se va a poder matar el pod y puede hacer que nuestro sistema no desescale. Hay que tener muy claro cuales son las necesidades y porque las estamos haciendo sino lo más normal es que nuestro clúster crezca sin sentido y no entendamos como está funcionando nuestro clúster.
Resumen
Kubernetes es una herramienta que requiere de un conocimiento previo bastante importante para poder llevarla a cabo. Tiene muchos conceptos que son más que indicar yo dockerizo mi aplicación y ya no tengo que saber nada de la infraestructura. Te abstrae en parte de la infraestructura, pero si que debes de conocer aspectos importantes como que recursos necesita para su ejecución, como queremos que se comporte ante cualquier fallo y como queremos que escale cuando sea necesario. AKS es un gran servicio, pero para el paso al uso de Kubernetes en los que equipos que lo utilicen deben tener claro cuál es la cultura DevOps y que se debe de monitorizar, analizar y volver a desplegar para tener un desarrollo optimo. Si nos dedicamos a desplegar sin más ... probablemente a la larga nos llevemos alguna sorpresa desagradable.
Dejaremos más adelante como queremos tunear nuestro clúster para llevar a cabo un optimo escalado sin morir en el intento
Happy Coding!
Adrián Diaz Cervera
Technical Lead at SCRM Lidl Hub International
Azure and M365 Development MVP
http://theavenger.dev
@AdrianDiaz81

